{kind=link}
Introduction
In the present day, IoT – the Internet of Things is employed for a series of engineering applications such as smart cities, smart manufacturing, self-directed driving, self-governing shipping, metropolitan surveillance, and smart industrialization. Irrespective of the fact that CC – Cloud Computing is promising in the enhancement through centralized approach, there are confronts like scalability, utilization of band-width, and privacy issues. To lessen these restrictions of cloud intensive systems, a matching approach called edge computing that seats data processing on the edge of the set of connections become emergent. In addition DRL – Deep reinforcement learning is also brought in to develop control policies to crack responsibilities autonomously. On the other hand, the supply boundaries, and with a great amount of levels and parameters of edge device makes it impractical to prepare their policies from basics. As the edge devices exercise pre-trained policies of centralized cloud structure with huge computational influence [1].
This makes the necessities for a method to efficiently convey refined knowledge to decide the behavior of edge contrivances with resource restrictions. Also there is a need for concurrent carrying out of knowledge and policy model for compression in a solo guiding procedure [2]. The requirement along with the explanation is discussed in the following sections of research report.
Edge Computing
Edge computing focuses networking and taking computing devices nearer to the source of information in the arrangement with the intention of reducing latency and utilization of band-width. This runs smaller number of processes in the cloud and further transferring them to neighboring seats like into an end-user’s workstation, IoT contrivance or edge server. This decreases the sum of long distance contact to take place involving a user and server [3].
Deep Reinforcement Learning
Reinforcement learning creates a novel paradigm swing with machine learning to permit agents settle on the chronological events for self-governing power. It facilitates agents to be trained on control strategy in a manner to capitalize on the anticipated return by means of a large number of trial and error communications among the background. DRL is a combination of reinforcement learning with deep neural networks to accomplish incessant controlling of events. DRL is an effortless and undemanding implementation with satisfactory assets for simulation but as tough to comprehend in a real time as the edge devices are operational with restricted hardware reserves [4].
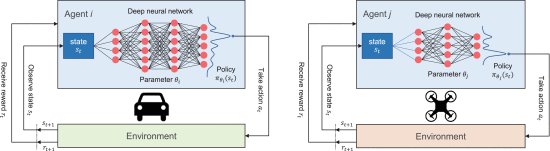
DRL in Edge Computing
DRL can be exercised in edge computing structure to deal with computation off-loading, supply orchestration and mobile edge caching to improve the network performance improvement. A series of hardware supply funds involving edge devices are to be considered to take DRL training for assorted edge contrivances. This takes advantage of both knowledge transfer as well as compression policy model for finding the solution. But for multifaceted tasks, it is impractical to prepare DRL guidelines from basics from a restricted resource plan. Furthermore, diverse hardware plans amongst edge devices are to be measured to carry DRL training for assorted edge mechanisms [5].
Edge Artificial Intelligence
An emerging AI – Artificial Intelligence base DRL presents a deep learning for the device – an agent to complete a task sound and have power over its actions by trial and error communications among an atmosphere. The fundamental of DRL is to prepare an effectual control policy / model through a strong approximation facility. DRL is realized as a means to facilitate edge devices to work out multifaceted tasks cleverly in real time applications. An on-device AI reflects on transferring knowledge of the pre-trained direct guidelines from the cloud to edge devices as well as to compress the policies based upon the hardware reserves. This necessitates enormous computational capacity and adequate hardware sources like CPU – Central Processing Unit and GPU – Graphics Processing Unit, RAM – Random Access Memory, ROM – Read-Only Memory, hard disk and electric supply. Edge AI techniques perform supposition or prediction and also carries out training. This as well presents intelligent edge services irrespective of hardware supplies. The edge and on-device smooth the progress of instant reaction, confidentiality continuance, and recovered ease of use in time of set of connections smash, better utilization of net band-width in cost-effective manner by putting artificial intelligence techniques into effect.
Knowledge Distillation
This approach communicates knowledge / transfer learning move to refine constructive acquaintance from a trainer model and convey it to a learner model. The distillation process transmits the distilled information from a trainer network to a learner network by making the most of softened targetsparameters. This is a transfer learning move towards distillation practical knowledge. This sharpened distributionendow with extra explicit information for activity choice as well providing a regression mark for the learner preparation. This distinctiveness makes DRL training process possible by accelerating the distillation [6].
OD3 – On device DRL with Distillation
The OD3 consents to an edge device for taking guidance of control policy on the hardware proposal by means of the distillation practice. This comes with 2 benefits such as acceleration of a policy training course of action of an edge device judging against that from scrape. In view of the fact that the OD3 takes up a sharpened target circulation to transmit a great deal of instantly recognizable knowledge that will result in a well acceptable deed for a specified circumstances; facilitates an edge contrivance to compress its direct guiding principle founded on the universal reserve financial plan by making the most of the conveyed knowledge from the cloud [7].
The innovation applied here is the knowledge distillation move toward to DRL powered edge device authority in incorporated edge cloud backgrounds. This is positive with edge policy preparation to achieve near cloud performance by means of standard returns, though the volume of the edge strategy network is considerably less significant weighing against the normal cloud policy set-up; the working out time beyond the edge policy preparation is notably decreased from the edge plan preparation from scrape.
An assortment of edge devices in multifaceted applications is necessary to formulate most favorable control actions with nominal human interference. Congregation of those load are possible with the up to date edge computing systems incorporating artificial intelligence at the
edge termed as edge AI or on-device termed to be on-device AI to deal with data processing as well as decision making for systematize the control.
OD3 Policy Model
The following diagram illustrates the edge computing architecture to efficiently train control policies on resource restricted- edge pieces of equipment, transferring the distilled knowledge from the cloud to edge devices and compressed conditional on their restricted resource resources [8]. This is made up of four layers edge devices, edge infrastructure, centralized cloud and applications. The knowledge from the cloud storage has been drawn with the help of knowledge distillation process. This yields on-device knowledge and may perhaps be very much valuable in policy model compression process.
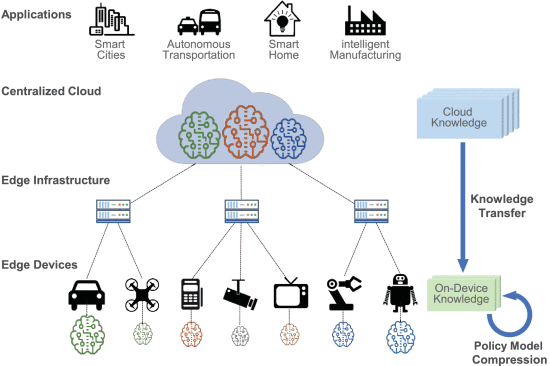
OD3 Policy Model
A deep learning based move is viable for solving real time issues of the edge computing coordination. Transferred knowledge is much helpful to construct a model competently irrespective of the availability of inadequate training data. The cutback on model complication is achievable taking account of policy model compression technique. The realization of on-device DRL for limited sources edge environment cooperates positively with cloud configuration. This addresses the multiplicity of resource limitations of individual edge tools. In addition exhibits the efficacy of applied distillation move toward the a real time issues.
Refined AI techniques in the subject of inference are applied to endow with quick edge services even if nearly all edge devices put up with from hardware resource limitations. The edge and on-device AI take part in a decisive payback to meet up the end user requirements within budget.
Conclusion
This research report on knowledge management discussed in detail regarding the method to competently transferring the distilled knowledge for DRL founded edge device direct in resource restricted edge computing systems that are referred as OD3 in short form. The purpose of the OD3 is to carry out knowledge transfer and policy representation compression at the same time in a solo training guiding principle on edge devices by influencing a knowledge distillation practice. The performance of a commercial rooted system-on-module prepared with some degree of hardware reserves. But OD3 achieves better overall show even though it consumes noteworthy minor policy network than that of the cloud environment. The value of the OD3 show the way for investigation on an effective method for engendering most advantageous neural network architectures by taking into the steadiness involving the presentation of the distilled guiding principle and the reserve restriction of the assorted edge devices, in addition to hyper parameter optimization for DRL in resource controlled edge environments consideration.
References
- B. &. N. K. &. R. S. Subramanian, ” IoT Technology, Applications and Challenges: A Contemporary Survey,” Wireless Personal Communications, 2019.
- H. Z. X. Chen, “Optimized computation offloading performance in virtual edge computing systems via deep reinforcement learning.,” IEEE Internet Things Journal, pp. 4005 – 4018, 2019.
- N. &. G. S. &. A. E. &. Y. I. &. I. M. Hassan, ” The Role of Edge Computing in Internet of Things.,” IEEE Communications Magazine., 2018.
- L. &. Z. Cao, “An Overview of Deep Reinforcement Learning.,” in 4th International Conference on Automation, Control and Robotics Engineering., 2019.
- F. &. Z. M. &. W. X. &. M. X. &. L. J. Wang, ” Deep Learning for Edge Computing Applications: A State-of-the-Art Survey,” IEEE Access, pp. 1-14, 2020
- J. &. W. S. &. E. A. &. O. S. &. J. E. &. C. H. &. K. H. &. K. S.-L. &. B. M. Park, “Distilling On-Device Intelligence at the Network Edge.,” 16 Aug 2019. [Online]. Available: https://www.researchgate.net/publication/335232398_Distilling_On-Device_Intelligence_at_the_Network_Edge. [Accessed 20 May 2021].
- I. &. K. S. &. K. H. &. P. C.-W. &. P. J. Jang, “An Experimental Study on Reinforcement Learning on IoT Devices with Distilled Knowledge.,” in International Conference on Information and Communication Technology Convergence , 2020.